
When you’re trying to shape the future while at the frontier, it’s hard to describe what is happening because, by nature, the space you’re entering is unexplored and undefined.
That’s the idea that Sequoia Capital (I think) rightly points out in the article “AI and the Frontier Paradox.” We should contextualize the current wave of AI promises with the innovations that have come before.
How AI Advancement Can Lead to Feedback Loops
When we look back at previous (and now familiar) AI frontiers, the definitions today are much narrower than the infinite possibilities they once implied. Good examples are Machine Learning and Computer Vision.
Let’s take the current excitement around Generative AI and LLMs and compare them with Machine Learning — using recommendation engines for music as an example. Many shortcomings in Machine Learning resulted in algorithmic feedback loops. And they could provide good insight into how to avoid similar pitfalls when training models on proprietary data.
There are dangers in letting AI optimize too sharply. Over time, the breadth of what is an acceptable response narrows as the AI starts to refine itself based on feedback from the world it has been influencing. The more our actions are informed or influenced by AI, the more the data we generate becomes shallower than it would be otherwise. The strongest metaphor I’ve seen is that models become photocopies of themselves, degrading with each round of training on their own outputs.
This is the kind of feedback loop that can quickly distort reality. It reinforces the success criteria introduced into the world by the model and not the criteria of the people it will influence, which can have unintended consequences.
I first encountered one of these algorithmic feedback loops when using the streaming music service Rdio (RIP) many years ago. One of the best features of a streaming service is how it ensures the music never stops (if that’s what you want) by offering “stations” based on the last song you intentionally played or an artist you choose as a seed. It is in these generated stations where, if you listen carefully enough for long enough, you start to hear how the algorithm works.
My last Spotify “Year in Review” had me in the top 5% of listeners in Canada, which would certainly be enough to hear patterns in my recommendations. I am sure I listened to Rdio that much, too.
I had been listening to a lot of Andrew Bird at the time, and he showed up often in my generated stations, which I was pleased to hear. However, one song kept playing over and over and over, despite the fact he had a good-sized back catalog: “Pulaski at Night.”
To be clear, this is a great song. I was happy to be introduced to it. It was a relatively new release at the time, though on a unique EP consisting mostly of instrumentals—hardly the kind of record that would get a big marketing push and unlikely to produce a traditional hit.
But the frequency with which it played and the speed with which it surpassed other songs of Bird’s in total play count led me to suspect that Rdio might be ingesting its recommendations or weighing the results of a recommendation that someone listened to in its entirety in such a way that momentum for the song began to grow, ultimately leading to it being played again, and again, and again.
This happened with other artists and songs, but nothing quite as repetitive as “Pulaski at Night.”
My memory might be fuzzy since this happened ten or so years ago. Researching this article revealed that the song was featured on Season 2 of Orange is the New Black, which was popular at the time. So, maybe the frequency of it showing up in my generated stations was, in fact, driven by listener demand for the song across Rdio, and the algorithm was working as intended, playing what “people like me” were listening to. Hard to say. At the time, I certainly had no way of knowing what was happening based on how these stations were presented to me.
Maybe what I experienced was non-algorithmic virality? Plausible.
But then it happened to me again recently on Spotify.
This time, the song was a demo version of “Come Play In The Milky Night” by Stereolab. It was released in 2019 as part of a reissue of the original 1999 album.
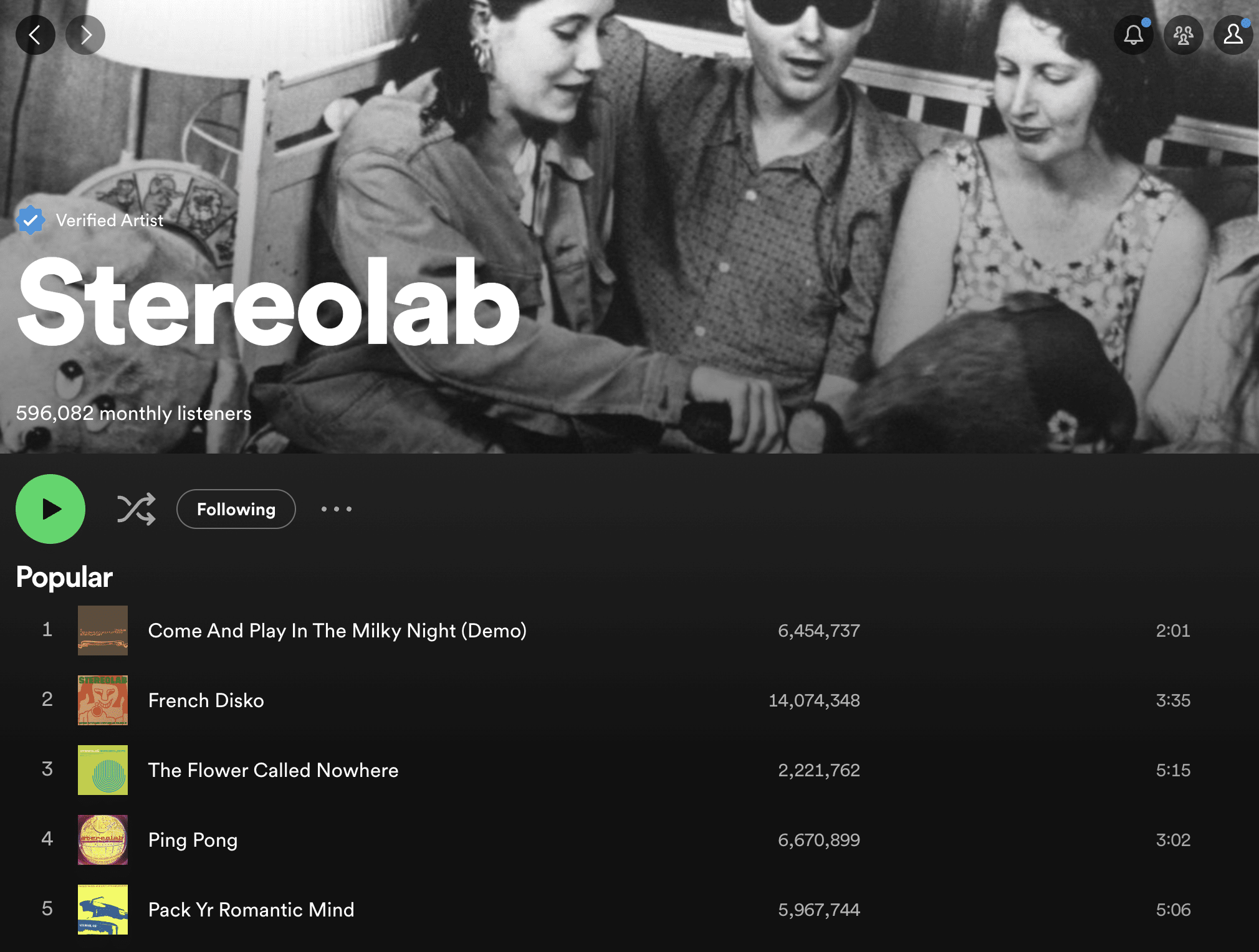
As I write this, the demo has amassed 6.4 million plays, while the original, which has been on Spotify for years longer, only has 1.8 million. So there have been triple the plays for the (admittedly excellent) demo than the (amazing) original release and over 100 times more plays than any other demo on the reissue.
If the song were truly sought after by listeners, the demo immediately following it on the reissue, “Strobo Acceleration” (also excellent), would get some spillover listens. Yet it only has 34 thousand plays. It’s clear that the majority of the 6.4 million plays are algorithmically driven by Spotify.
That Stereolab songs might be played disproportionately on my generated stations is not surprising as they’ve been my top artist on Spotify for years. But that this one song gets played over and over is, considering how much I listen to the rest of their catalog.
The Consequences of GenAI and Feedback Loops
If this is a feedback loop where Spotify ingested its own recommendations as a signal of user intent, what are the consequences? Stereolab gets a late-career streaming micro-hit as a result of an algorithmic distortion, big deal.
But streaming is a zero-sum game where a fixed pool of royalties is dispersed proportionally (sort of, but not really) according to the number of plays. So, this kind of hit-making hallucination can have a material impact on an artist’s revenue. For an established catalog artist like Stereolab, it might not make a big difference. But for a new artist trying to break through against the dominance of back catalog (70% of total plays on Spotify go to what they define as catalog), it can be the difference between a career and a hobby.
One Spotify distortion, one hallucinated hit, could theoretically launch an artist or give a false signal that an audience exists. Hard to say because the underlying algorithm is opaque, and there are no tools for interrogation.
As an aside, UMG and Deezer announced that they were launching a new monetization model to more fairly compensate artists. One feature of the new model is “additionally assigning a double boost for songs that fans actively engage with, reducing the economic influence of algorithmic programming.” This is a welcome step towards rebalancing power away from the platforms and into the fan’s hands.
The design of visibility into AI systems is a whole other topic. For now, I want to emphasize that these two examples are likely but two of an unknowable number of distortions. Maybe Spotify has tools that help them identify and correct feedback loops like they now do with spam songs that tag established artists. Or, perhaps it is simply an acceptable side-effect of tasking algorithms with keeping the music flowing. While hard to see and hear unless you’re paying unreasonable attention, it is happening and happening inside the constrained boundaries of a well-maintained product.
But what are the consequences when GenAI is unleashed on the broader open internet? How many feedback loops will go undetected, and to what effect?
It has already been reported that content farms are using GenAI to create junk websites optimized for ad revenue. The major consequence of using GenAI to optimize for specific algorithmic outcomes is a cratering of quality. It doesn’t matter if the junk site provides hallucinated medical advice so long as it generates impressions.
If you thought Buzzfeed-list headlines were gaming the internet, just wait until GenAI agents start to compete with each other over SEO, ingesting each other’s tactics along the way. Such a feedback loop will render searching the internet for quality results even more difficult than the current ad-stuffed Google experience.
That is one example of GenAI ingesting itself on the horizon in the broader open internet. An example that may or may not be easy to spot in the future. But what should companies looking to train models on their own proprietary data look out for in order to avoid feedback loops of their own?
How Companies Can Avoid Feedback Loops When Utilizing GenAI
The first thing to consider is what problem you want to solve with GenAI.
Cost reduction through automation is one of the most common initial applications. However, be careful with that approach, especially for systems trained on internal data, because your future training data (i.e. the interactions your customers have with your product or service) will be influenced by the outputs of your AI systems. And if you take that data at face value and use it for future training, you’ve created a loop.
If you intend to use GenAI to automate processes, consider how to include humans in the overall service as quality control over the outputs and monitor the resulting outcomes. What you might save in short-term efficiency by fully automating processes with GenAI, you may eventually lose over poor quality future data.
For AI chatbots or recommendation engines, the false positive feedback loop is the one to look out for.
Like these song examples, if the success criteria for the algorithm are slightly misaligned with the user’s true intent, but the user does what was recommended (listen to the song, for example, or try a troubleshooting approach, or sign up for an add-on service) soon the suggested path becomes the reinforced default.
While not a total failure, it will make it harder to identify other, better paths for the user because the paths not taken won’t show up in your data. Those are normally caught by a product team that stays close to their customers.
As a result, one potentially negative consequence could be losing visibility into the changing needs of your customers. AI systems are very good at pattern matching against prior data. However, they will struggle to tease out new opportunities.
The irony here is that while GenAI is undoubtedly innovative and could help with efficiency, it could also eliminate valuable channels of future innovation and growth for your business because it will not be able to identify a problem as an opportunity. And if you’ve implemented it with unintended feedback loops, it will inevitably optimize to the point where even when it has a million options to present to you, it will present the same one that worked most recently.
The biggest assumption being made in GenAI is that the future will look like the past. What you wanted to hear yesterday is the same as today. If we want AI systems that get better over time and truly fulfill their potential, they will have to be implemented in a way that allows for new divergent paths and course correction. Otherwise, we’ll find ourselves running in loops.



